Tensor Parallelism에 대해서 먼저 살펴 보겠습니다.
Tensor Parallelism
Tensor Parallelism은 모델을 여러개의 GPU에 분산하여 학습하거나 추론하는 방법입니다.
이 방법은 모델의 크기가 커지면서 메모리가 부족해지는 문제를 해결하기 위해 사용됩니다.
Tensor Parallelism의 기본 아이디어는 다음과 같습니다.
tesnor와 tensor의 matrix multiplication은 곱해지는 tensor를 분할하여, 각각의 부분을 곱한 다음 결과를 합치는 것과 같기 때문에,
tensor를 분할하여 여러 GPU에 분산하여 계산하면, 계산 속도를 높일 수 있다는 것이죠.
예를 들어, 두 개의 행렬 A와 B가 있다고 할 때:
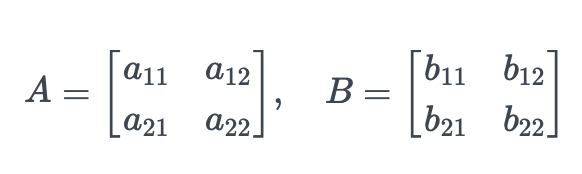
A의 행과 B의 열을 각각 곱한 후 더해서 새로운 행렬 C를 만들어야 합니다.
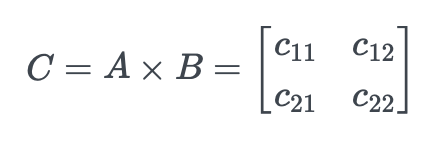
여기서:

이 계산을 하나의 GPU가 혼자 한다고 생각하면, time(C_{11}) + time(C_{12}) + time(C_{21}) + time(C_{22}) 시간이 걸릴 것입니다.
하지만 이 계산을 4개의 GPU가 나눠서 한다면 time(C_{11}), time(C_{12}), time(C_{21}), time(C_{22}) 중, 가장 오래 걸리는 계산을 시간 time{C_{result}}이라고 하면, 이 시간과 각각의 계산을 모두 더하는 계산의 시간 time{C_{calc}}이 걸릴 것입니다.
이 시간이 하나의 GPU에서 계산하는 것보다 훨신 짧을 것입니다.
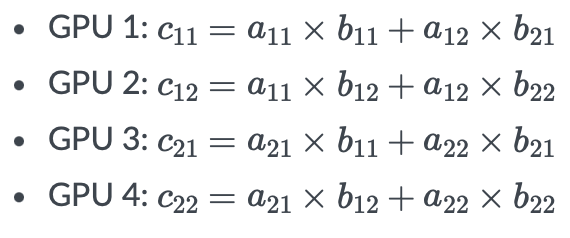
여기에서 좀 더 생각해볼 문제가 있습니다. 각 GPU가 계산한 결과를 더하기 위해서는, GPU가 서로 통신을 해야 한다는 것이죠.
이 때 데이터가 이동하는데 시간이 걸리고, 이걸 일반적으로 communication overhead라고 부릅니다.
따라서 각 GPU에 분산하여 수행할 작업이 매우 큰 상태라서 계산 시간이 communication overhead보다 훨씬 크다면, tensor parallelism을 사용하는 것이 효과적일 것입니다.
TGI 소개 페이지에서는 "for faster inference" 라고 설명하고 있는데, 잘 이해가 되지는 않습니다.
하나의 GPU에 로드 될 수 있는 모델을 여러 GPU에 tensor parallelism을 이용해 분산 로드 하면 communication overhead가 발생하게 되어 오히려 느려질 것 같은데 말입니다. 대규모 모델의 경우에는 애초에 하나의 GPU에 로드될 수 없기 때문에, inference 성능을 높이기 위해서가 아니라, 모델 로드를 하기 위해서 tensor parallelism을 사용하는 것이라고 생각 됩니다. (NVLink처럼 매우 빠른 통신이 가능하다면 성능은 향상 되겠죠 😀)
실제 코드에서는 어떻게 구현되어 있는지 살펴보겠습니다.
Tensor Parallelism 구현 리뷰
총 6개의 class로 구성되어 있습니다.
- LayerConcat class
- SuperLayer class
- TensorParallelHead class
- TensorParallelColumnLinear class
- TensorParallelRowLinear class
- TensorParallelEmbedding class
각 class는 다음과 같은 역할을 합니다.
LayerConcat class
LayerConcat class는 이름에서 알 수 있듯이, 여러 layer의 출력을 연결(concatenate)하여 하나의 출력으로 반환합니다.
forward() method에서 입력 받은 tensor x를 각각의 layer에 넣어서 출력을 받은 후, torch.cat()을 이용하여 연결하고, 그 결과를 반환하고 있습니다.
def forward(self, x: torch.Tensor):
outputs = [layer(x) for layer in self.layers]
return torch.cat(outputs, self.dim)
이 class에서 중요한 변수는 dim입니다.
def __init__(self, layers: Iterable[torch.nn.Module], dim: int = -1):
"""
`dim` is the dimension along which layer outputs are concatenated.
"""
super().__init__()
self.layers = layers
self.dim = dim
dim은 torch.cat()을 이용하여 tensor를 연결할 때, 어느 차원을 기준으로 연결할 것인지를 나타냅니다.
이 부분을 이해하기 위해서, tensor의 차원에 대해 살펴 보겠습니다.
tensor는 다차원 배열로, 각 차원은 서로 다른 축을 나타냅니다.
예를 들어 2차원 tensor는 행과 열로 구성된 배열, 3차원 tensor는 행, 열, 깊이를 가진 배열이라고 생각할 수 있죠.
tensor의 각 차원에는 index가 있으며, 0부터 시작합니다.
[batch_size, num_features] 형태의 2차원 tensor를 예로 들면,
- dim=0: batch_size (행)
- dim=1: num_features (열) 을 나타내는 것입니다.
그리고 torch.cat() 함수는, 여러 tensor를 지정된 차원에서 연결하여 하나의 tensor로 만들어주는 함수입니다.
예를 들면, 위의 [batch_size, num_feature] 형태를 갖고, [2, 3] 크기의 tensor A, B가 있을 때, dim=0에서 연결하면 A와 B가 행 방향으로 붙게 되어 [4, 3] 크기의 tensor가 됩니다. dim=1에서 연결하면 열 방향으로 붙어서 [2, 6] 크기의 tensor가 됩니다.
이것의 의미는, dim=0에서 연결하면 결과 tensor들이 쌓이면서 batch size가 증가하고, dim=1에서 연결하면 같은 batch 내에서 각 feature들이 더해지면서 feature 크기가 커진다는 것입니다.
따라서 개발자는 이 class를 통해, 각 tensor가 어떻게 연결될지를 세밀하게 제어할 수 있고 다양한 tensor 연산을 수행할 수 있게 될 것입니다.
SuperLayer class
이 class는 단순하게 하나의 linear layer를 포함하는 클래스로, forward() method에서 입력 tensor를 linear layer에 넣어서 출력을 반환합니다.
def forward(self, x):
return self.linear.forward(x)
이름에서 알 수 있듯이 상속을 통해 확장하기 위한 class 입니다.
TensorParallelHead class
TensorParallelHead class는 tensor parallelism에서 모델의 마지막 layer(head)를 병렬로 처리하기 위한 class입니다.
load() method
load() method는 모델을 로드할 때 사용할 적절한 파라미터를 설정하고, weight를 분할하여 여러 GPU에 로드합니다.
def load(config, prefix: str, weights):
if config.quantize == "exl2":
try:
# If the piece and LM head embeddings are shared, we have
# non-quantized weights...
weight = weights.get_tensor(f"{prefix}.weight")
except Exception:
# ...otherwise they are quantized.
weight = weights.get_weights_col(prefix)
should_gather = weights.process_group.size() > 1
elif weights.process_group.size() > 1:
try:
weight = weights.get_sharded(f"{prefix}.weight", dim=0)
should_gather = True
except AssertionError:
# If the vocab size is not divisible by number of shards
# just load the entire thing.
weight = weights.get_tensor(f"{prefix}.weight")
should_gather = False
else:
weight = weights.get_tensor(f"{prefix}.weight")
should_gather = False
return TensorParallelHead(
get_linear(weight, bias=None),
process_group=weights.process_group,
should_gather=should_gather,
)
이 method에서는 총 3개의 parameter를 받고 있습니다.
- config: 모델 구성을 담고 있는 객체로, 양자화 방식, process group (병렬 처리에 사용하는 GPU 그룹) 등의 설정이 포함되어 있습니다.
- prefix: weight를 가져올 때 사용할 prefix입니다.
- weights: weight들을 관리하는 객체로, weight를 가져오거나, 분할된 가중치를 결합하는 기능을 제공하고 있습니다.
조건문에 의한 분기는 총 3가지 경우로 나뉩니다.
- exl2 양자화 방식을 사용하는 경우
- process group의 크기가 1보다 큰 경우
- process group의 크기가 1인 경우
exl2 양자화 방식을 사용하는 경우에는, weight를 가져오는 방식이 다릅니다.
양자화된 경우, weight.get_weights_col() method를 사용하여 weight를 가져오고, 양자화되지 않은 경우, weight.get_tensor() method를 사용하여 weight를 가져옵니다.
if config.quantize == "exl2":
try:
# If the piece and LM head embeddings are shared, we have
# non-quantized weights...
weight = weights.get_tensor(f"{prefix}.weight")
except Exception:
# ...otherwise they are quantized.
weight = weights.get_weights_col(prefix)
should_gather = weights.process_group.size() > 1
process group의 크기가 1보다 큰 경우는, weight가 여러 GPU에 분산되어 있을 수 있습니다. (sharding)
이 경우, weight.get_sharded() method를 사용하여 weight를 가져오고, should_gather를 True로 설정합니다.
만약 sharding된 weight를 가져오는 중에 문제가 발생하면 (AssertionError), 전체 weight를 불러 오도록 처리하고 있습니다.
elif weights.process_group.size() > 1:
try:
weight = weights.get_sharded(f"{prefix}.weight", dim=0)
should_gather = True
except AssertionError:
# If the vocab size is not divisible by number of shards
# just load the entire thing.
weight = weights.get_tensor(f"{prefix}.weight")
should_gather = False
process group의 크기가 1인 경우는, weight를 가져오는 방법이 가장 간단합니다. 병렬 처리가 필요 없기 때문이죠.
else:
weight = weights.get_tensor(f"{prefix}.weight")
should_gather = False
마지막으로 get_linear(weight, bias=None)을 통해 weight를 가지고 Linear layer를 생성하고, TensorParallelHead class를 생성하여 반환합니다.
should_gather는 나중에 병렬 처리 중 weight를 결합할 필요가 있는지를 나타냅니다. 이 값이 어떻게 쓰이는지는 아래 forward() method에서 살펴보겠습니다.
return TensorParallelHead(
get_linear(weight, bias=None),
process_group=weights.process_group,
should_gather=should_gather,
)
forward() method
forward() method는 input tensor를 병렬 처리하고, 필요 시 여러 GPU의 출력을 모아서 반환합니다.
def forward(self, input: torch.Tensor) -> torch.Tensor:
if not self.should_gather:
return super().forward(input)
world_size = self.process_group.size()
if len(input.shape) == 2 and isinstance(self.linear, FastLinear):
out_dim = self.linear.weight.shape[0]
if input.shape[0] == 1:
world_out = input.new_empty(1, out_dim * world_size)
local_out = input.new_empty(1, out_dim)
gather_input = local_out
else:
world_out = input.new_empty(out_dim * world_size, input.shape[0])
gather_input = input.new_empty(out_dim, input.shape[0])
local_out = gather_input.T
torch.mm(input, self.linear.weight.T, out=local_out)
if SYSTEM == "ipex":
ipex.distributed.all_gather_into_tensor(
world_out, gather_input, group=self.process_group
)
else:
torch.distributed.all_gather_into_tensor(
world_out, gather_input, group=self.process_group
)
if input.shape[0] == 1:
return world_out
return world_out.T
output = super().forward(input)
world_output = [
torch.empty_like(output) for _ in range(self.process_group.size())
]
if SYSTEM == "ipex":
ipex.distributed.all_gather(world_output, output, group=self.process_group)
else:
torch.distributed.all_gather(world_output, output, group=self.process_group)
world_output = torch.cat(world_output, dim=-1)
return world_output
self.should_gather가 False인 경우에는, 병합이 필요 없으므로, super().forward(input)을 호출하여 결과를 반환합니다.
if not self.should_gather:
return super().forward(input)
함수의 구현은 크게 2가지 경우로 나뉩니다.
- input tensor가 2차원이고, Linear layer가 FastLinear인 경우
- 그 외의 경우
아래처럼, input tensor가 2차원이고, Linear layer가 FastLinear인 경우인지 확인하고,
world_size = self.process_group.size()
if len(input.shape) == 2 and isinstance(self.linear, FastLinear):
해당 경우에는 아래와 같이 처리하고 있습니다.
if input.shape[0] == 1:
world_out = input.new_empty(1, out_dim * world_size)
local_out = input.new_empty(1, out_dim)
gather_input = local_out
else:
world_out = input.new_empty(out_dim * world_size, input.shape[0])
gather_input = input.new_empty(out_dim, input.shape[0])
local_out = gather_input.T
먼저, input tensor의 첫 번째 차원 (batch size)이 1인 경우와 아닌 경우로 나누어 처리하고 있습니다.
world_out tensor는 각 GPU에서 계산된 결과를 저장할 tensor이고, local_out tensor는 각 GPU에서 계산된 결과를 저장할 tensor입니다. out_dim은 출력 차원, world_size는 병렬 처리에 참여하는 GPU의 수입니다.
batch size가 1인 경우, world_out tensor를 생성할 때, out_dim * world_size 크기로 생성합니다.
batch size가 1이므로, 모든 GPU에서 계산된 결과가 하나의 열에 저장됩니다.
local_out tensor를 생성할 때, out_dim 크기로 생성합니다. local_out tensor에 input tensor와 wiehgt 행렬 간의 곱셈 결과를 담고,
이 결과는 이후 gather_input으로 사용되어, 모든 GPU의 결과를 world_out tensor로 병합하는 것이죠.
batch size가 1이 아닌 경우에는, world_out tensor를 생성할 때, out_dim * world_size, batch size 크기로 생성하고,
gather_input tensor를 생성할 때도, out_dim, batch size 크기로 생성합니다.
여러 개의 input이 처리 되기 때문에, 각 batch에 대해서 GPU에서 계산된 결과를 포함하는 더 큰 tensor (out_dim * world_size, batch_size)가 필요하고, 각 batch마다 병합된 결과를 보관합니다.
다음으로, matrix multiplication을 수행하고, 결과를 local_out tensor에 저장합니다.
torch.mm(input, self.linear.weight.T, out=local_out)
그리고 분산된 여러 GPU에서 계산된 결과를 하나의 텐서로 합치는 작업을 수행하는데,
IPEX (Intel Extension for PyTorch)와 PyTorch의 분산 처리 함수를 사용하여 처리하고 있습니다.
all_gather_into_tesor()는 gather_input tensor를 world_out tensor로 병합합니다.
if SYSTEM == "ipex":
ipex.distributed.all_gather_into_tensor(
world_out, gather_input, group=self.process_group
)
else:
torch.distributed.all_gather_into_tensor(
world_out, gather_input, group=self.process_group
)
마지막으로 결과를 반환합니다. input tensor의 batch size가 1인 경우는 그대로 반환하고,
그렇지 않은 경우에는 world_out tensor를 반환할 때, result tensor의 shape이 다르기 때문에 transpose를 수행하여 결과를 반환합니다.
if input.shape[0] == 1:
return world_out
return world_out.T
다시 맨 처음으로 돌아가서, FastLinear 처리가 아닌 경우에는 다음과 같이 처리하고 있습니다.
부모 클래스의 forward() method를 사용하여 output이 생성되고, 이를 다시 all_gather를 통해 여러 GPU에서 병합한 후, 반환합니다.
output = super().forward(input)
world_output = [
torch.empty_like(output) for _ in range(self.process_group.size())
]
if SYSTEM == "ipex":
ipex.distributed.all_gather(world_output, output, group=self.process_group)
else:
torch.distributed.all_gather(world_output, output, group=self.process_group)
world_output = torch.cat(world_output, dim=-1)
return world_output
TensorParallelColumnLinear class
이 class는 특정 모델의 tensor parallelism과 관련된 연산을 효율적으로 수행하기 위해 구현되었습니다.
method들을 차례로 살펴 보면, 다음과 같습니다.
load_gate_up() method
이 method의 구현은 간단합니다. get_weights_col_packed_gate_up() method를 사용하여, prefix를 통해 (패킹된)특정 weight를 가져오고, - 예를 들어, prefix가 layer1이라면, layer1.weight를 가져옵니다.
해당 계층에 bias가 없는 경우 (bias가 False) 에만, linear layer를 생성하고 인스턴스를 반환합니다.
QKV 연산이 병렬로 처리된 이후 가중치를 가져오는 method입니다.
@classmethod
def load_gate_up(cls, config, prefix: str, weights, bias: bool):
"""Specific method when the QKV was joined after the fact"""
weight = weights.get_weights_col_packed_gate_up(prefix)
if bias:
raise NotImplementedError("packed_gate_up only implemented without bias")
else:
bias = None
linear = get_linear(weight, bias)
return cls(linear)
load_qkv() method
load_gate_up() method와 비슷하게, get_weights_col_packed_qkv() method를 사용하여, prefix를 통해 OKV 벡터가 패킹된 특정 weight를 가져오고,해당 계층에 bias가 없는 경우 (bias가 False) 에만, linear layer를 생성하고 인스턴스를 반환합니다.
num_heads와 num_key_value_heads는 각각 multi-head attention의 head 수와 key, value head의 수를 나타냅니다.
위에서 살펴 본 load_gate_up() method와 비슷한 구조를 가지고 있어서 어떤 차이점이 있는지 좀 더 살펴 보면, 주된 차이점은 두 method가 다루는 데이터의 성격과 목적에 있습니다.
@classmethod
def load_qkv(
cls,
config,
prefix: str,
weights,
bias: bool,
num_heads: int,
num_key_value_heads: int,
):
"""Specific method when the QKV was joined after the fact"""
weight = weights.get_weights_col_packed_qkv(
prefix,
num_heads=num_heads,
num_key_value_heads=num_key_value_heads,
)
if bias:
raise NotImplementedError("packed_qkv only implemented for baichuan")
else:
bias = None
linear = get_linear(weight, bias)
return cls(linear)
load_gate_up()의 경우에는 QKV (Query, Key, Value) 벡터가 "gate up" 상태에서 결합된 후 패킹된 가중치를 로드하는 method 입니다. load_qkv()의 경우에는 멀티헤드 어텐션에서 사용되는 QKV 벡터를 처리하기 위한 method로, 각 QKV 벡터가 여러 헤드로 나뉘어 패킹된 상태에서 weight를 가져옵니다.
load() method
이 method 역시 비슷한 구조를 갖고 있는데, bias가 있는 경우에 대한 처리가 추가되어 있습니다.
bias가 있는 경우에는 get_sharded() method를 사용하여 bias를 sharding된 상태로 가져오고, 이를 이용하여 linear layer를 생성합니다.
@classmethod
def load(cls, config, prefix: str, weights, bias: bool):
weight = weights.get_weights_col(prefix)
if bias:
bias = weights.get_sharded(f"{prefix}.bias", dim=0)
else:
bias = None
linear = get_linear(weight, bias)
return cls(linear)
load_multi() method
@classmethod
def load_multi(cls, config, prefixes: List[str], weights, bias: bool, dim: int):
if config.quantize == "exl2":
linears = []
for prefix in prefixes:
weight = weights.get_weights_col(prefix)
b = weights.get_tensor(f"{prefix}.bias") if bias else None
linears.append(get_linear(weight, b))
linear = LayerConcat(linears)
else:
weight = weights.get_multi_weights_col(prefixes, dim=dim)
if bias:
b = [weights.get_sharded(f"{p}.bias", dim=0) for p in prefixes]
bias = torch.cat(b, dim=dim)
else:
bias = None
linear = get_linear(weight, bias)
return cls(linear)
다른 method들과 약간 다른 구조를 가지고 있습니다. 먼저 양자화 설정에 따른 분기가 있습니다.
양자화 방식이 exl2인 경우, 각 prefix에 대해 weight와 bias를 가져와서 linear layer를 생성하고, 이를 LayerConcat class를 이용하여 연결합니다.
if config.quantize == "exl2":
linears = []
for prefix in prefixes:
weight = weights.get_weights_col(prefix)
b = weights.get_tensor(f"{prefix}.bias") if bias else None
linears.append(get_linear(weight, b))
linear = LayerConcat(linears)
양자화 방식이 exl2가 아닌 경우에는, get_multi_weights_col() method를 사용하여 weight를 가져옵니다.
get_multi_weights_col() method는 여러 개의 prefix에 대한 weight를 한 번에 로드합니다. dim은 이 weight들이 결합될 차원을 지정하고요. 그 외 bias load나 torch.cat()과 같은 부분은 위에서 설명한 것과 동일합니다.
여러 개의 weight과 bias를 병합하여 단일 linear layer를 생성하는 방식으로, 다증 계층의 출력을 하나의 linear 연산으로 처리 할 때 사용합니다.
else:
weight = weights.get_multi_weights_col(prefixes, dim=dim)
if bias:
b = [weights.get_sharded(f"{p}.bias", dim=0) for p in prefixes]
bias = torch.cat(b, dim=dim)
else:
bias = None
linear = get_linear(weight, bias)
TensorParallelRowLinear class
이 class는 TensorParallelColumnLinear class와 비슷한 역할을 수행합니다.
모델의 weight를 행(row) 단위로 병렬 처리하고, 다중 GPU에서 연산된 결과를 효율적으로 병합하는 기능을 제공합니다.
load() method는 다음과 같이 구현되어 있습니다.
@classmethod
def load(cls, config, prefix: str, weights, bias: bool):
weight = weights.get_weights_row(prefix)
if bias and weights.process_group.rank() == 0:
# Rank is only on the first rank process
bias = weights.get_tensor(f"{prefix}.bias")
else:
bias = None
return cls(
get_linear(weight, bias),
process_group=weights.process_group,
)
weights.get_weights_row() method를 사용하여, prefix를 통해 행 단위로 weight를 가져오고,
bias가 있는 경우에는 rank가 0인 process에서 bias를 가져오고, 그렇지 않은 경우에는 None으로 설정합니다.
rank가 0이라는 의미는 첫 번째 GPU에서만 bias를 가져오겠다는 의미입니다.
모든 GPU에서 bias를 가져오면, 중복 로드가 발생하여 메모리 낭비가 될 수 있기 때문이죠.
forward() method는 다음과 같이 구현되어 있습니다.self.process_group_size() > 1 and reduce가 True인 경우에만, all_reduce() method를 사용하여, 여러 GPU에서 계산된 결과를 모아서 반환합니다.
def forward(self, input: torch.Tensor, reduce: bool = True) -> torch.Tensor:
out = super().forward(input)
if self.process_group.size() > 1 and reduce:
if SYSTEM == "ipex":
ipex.distributed.all_reduce(out, group=self.process_group)
else:
torch.distributed.all_reduce(out, group=self.process_group)
return out
TensorParallelEmbedding class
이 class는 분산 환경에서 embedding layer를 병렬 처리하기 위해 설계된 클래스 입니다.
여러 GPU에 걸쳐 embedding weight를 분산시키고, 이 분산된 weight를 사용하여 효율적으로 embedding 연산을 수행합니다.
init() method가 이 파일 내에 구현된 class들 중 가장 복잡한(🤪) 구조를 가지고 있습니다.
def __init__(self, prefix: str, weights, reduce=True):
super().__init__()
weight = weights.get_partial_sharded(f"{prefix}.weight", dim=0)
num_embeddings = weights.get_shape(f"{prefix}.weight")[0]
process_group = weights.process_group
world_size = process_group.size()
rank = process_group.rank()
block_size = (num_embeddings + world_size - 1) // world_size
self.min_id = rank * block_size
self.max_id = min(num_embeddings, (rank + 1) * block_size)
self.null_idx = weight.shape[
0
] # Usually block_size, might be less in non even vocab_size.
self.process_group = weights.process_group
self.reduce = reduce
"""Additional 0 entry used for masking"""
self.weight = torch.nn.Parameter(F.pad(weight, (0, 0, 0, 1)))
weight.get_partial_sharded() method에서는 embedding table을 특정 차원(dim=0)에서 sharding 합니다.
이 과정에서 각 GPU에 전체 ebmedding table의 일부가 할당됩니다. 이를 통해 메모리 사용량을 줄이고 병렬 연산의 효율성을 높입니다.
num_embedding는 전체 embedding table의 크기입니다.
block_size는 각 GPU가 처리할 embedding의 범위가 되는데, 전체 embedding 수를 GPU 수로 나눈 값이 됩니다.
min_id와 max_id는 각 GPU가 처리할 embedding의 범위를 나타냅니다. 이를 통해 각 GPU가 자신에게 할당된 embedding만을 처리하게 됩니다.
null_idx는 범위를 벗어나는 경우에 사용할 값으로, embedding table에서 유효하지 않은 인덱스가 발생 할 때, 이를 null index로 처리하기 위해 사용합니다.
마지막으로 masking을 위한 padding을 추가하여, weight tensor를 생성합니다.
sharding된 weight에 추가적으로 0을 사용하여 padding을 추가하는데, 이는 embedding 과정에서 발생할 수 있는 masking을 처리하기 위한 것입니다. padding이란 tensor의 크기를 늘리기 위해 특정 값을 추가하는 작업을 의미합니다.
F.pad(weight, (0, 0, 0, 1))의 의미는 마지막 차원에 1개의 0을 추가한다는 의미입니다.
embedding 과정에서 input tensor의 인덱스가 주어진 범위를 벗어나는 경우, null index로 처리하게 되는데, 이 때 이 padding된 항목을 참조하게 됩니다.
forward() method는 다음과 같이 구현되어 있습니다.
input tensor를 받아 embedding 연산을 수행하고, 결과를 반환하고 있습니다.
def forward(self, input: torch.Tensor) -> torch.Tensor:
# default all out of bounds values to `self.null_idx` that will then be mapped to 0
# translate for [0, self.max_id - self.min_id[
input = torch.where(
(self.min_id > input) | (input >= self.max_id),
self.null_idx,
input - self.min_id,
)
out = torch.nn.functional.embedding(input, self.weight)
if self.reduce and self.process_group.size() > 1:
if SYSTEM == "ipex":
ipex.distributed.all_reduce(out, group=self.process_group)
else:
torch.distributed.all_reduce(out, group=self.process_group)
return out
torch.where() method를 사용하여, input tensor의 인덱스가 현재 GPU가 처리할 수 있는 범위 내에 있는지 확인하고, 범위가 벗어나면 null_idx로 대체합니다.
범위 내의 유효한 인덱스는 현재 GPU가 처리할 수 있도록 min_id 기준으로 조정합니다. 이후 torch.nn.functional.embedding() method를 사용하여, embedding 연산을 수행합니다. 위에서 변환된 인덱스를 사용하여, embedding table에서 해당 인덱스에 해당하는 값을 찾아서 반환합니다.
마지막으로 reduce가 True이고, 병렬 처리가 필요한 경우에는 all_reduce() method를 사용하여, 여러 GPU에서 계산된 결과를 모아서 반환합니다. 아닌 경우에는 그대로 결과를 반환하면 되겠죠.
결론
이상으로 TGI의 tensor parallelism 구현에 대한 리뷰를 마치겠습니다.
tensor_parallel.py 파일에 구현된 class들은 tensor parallelism을 사용하여 모델의 weight를 효율적으로 분산하고,
여러 GPU에서 계산된 결과를 효율적으로 병합하는 기능을 제공하고 있습니다. 실제 inference 과정에서 어떻게 사용되는지는 다음 리뷰에서 살펴보겠습니다
'Tech' 카테고리의 다른 글
| [AI상식] LLM은 어떻게 동작할까 - Embedding (6) | 2025.02.01 |
|---|---|
| Deepseek v3 code review - model (0) | 2025.01.30 |
| TGI Review - server (0) | 2025.01.29 |
| Text Generation Interface (TGI) Review (0) | 2025.01.29 |
| Rust toy project (0) | 2023.04.29 |