https://unnamed-underdogs.tistory.com/32
DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale #1
https://arxiv.org/pdf/2201.05596 거대 dense 모델의 훈련 비용과 관련하여 하드웨어 리소스의 가용성과 용량 한계를 극복할 수 있는 기술로 MoE(Mixture of Experts) 기술이 소개되었습니다. 하지만 모델 크기
unnamed-underdogs.tistory.com
1탄에 이어, 2탄을 진행해 보겠습니다.
MoE 추론 성능은 전체 모델 크기와 달성 가능한 메모리 대역폭이라는 두 가지 주요 요소에 의존합니다. 왜냐하면 MoE 모델의 파라미터 수가 많을수록 더 많은 메모리와 계산 자원이 필요하게 되어 성능에 영향을 미치고, 모델 크기가 클수록 메모리 대역폭의 수요도 증가하게 됩니다. 또 메모리 대역폭은 데이터가 메모리에서 프로세서로 얼마나 빠르게 전송될 수 있는지를 나타내는 것으로, 이 수치가 높으면 데이터 처리 속도가 빨라져 MoE 모델의 추론 성능이 향상되겠죠. 여러 GPU가 연결된 시스템에서는 집합된 메모리 대역폭을 활용하여 더 빠른 처리 속도가 가능해집니다.
1부에서는 PR-MoE와 MoS를 통해 모델 크기를 줄이면서도 모델의 정확도를 유지하는 방법에 대한 내용을 살펴 봤고, 이번에는 다중 GPU MoE 추론 시스템을 어떻게 구축하여 달성 가능한 메모리 대역폭을 극대화하는 시스템 최적화 솔루션을 만들었는지에 대한 내용을 살펴 보겠습니다.
1.3B-MoE-128 모델을 표준 MoE, Top 1 게이팅 방식으로 추론에 사용한다고 하면, 1.3B의 파라미터가 필요하게 되는데, 실제 전체 파라미터의 크기는 52B 입니다. 문제는 최악의 경우, 모든 토큰 별로 모두 다른 expert를 활성화 한다고 가정해보면 배치 내 토큰을 처리하는데 필요한 총 파라미터가 1.3B가 아닌, 52B가 되어버려 추론 레이턴시가 길어질 수 있다는 것입니다. (처리량도 떨어지고요)
그래서 DeepSpeed-MoE에서는 \세 가지 종류의 잘 조율된 최적화를 통해 이를 해결하고자 했습니다. 서로 다른 유형의 parallelism을 사용하여 모델을 분할하여 병렬성을 높입니다. 그리고 동일한 데이터 경로를 가진 모든 토큰을 함께 그룹화하고 라우팅하여 장치 당 데이터 액세스를 줄이고 최대 집합 대역폭을 달성하고, 장치 당 성능을 향상시키기 위해 transformer 및 MoE 관련 커널을 최적화했습니다. 이 내용에 대해서 살펴 보겠습니다.
먼저 Tensor-Slicing, Expert-Slicing, Data Parallelism, Expert Parallelism의 조합 사용에 대한 내용입니다.

그림을 간단히 살펴 보면, 노드 내에서 텐서-분할을 사용하여, 집합 GPU 메모리를 활용하여 더 큰 non-expert(attention layer) 파라미터를 허용하면서 노드 내 모든 GPU의 집합 메모리 대역폭을 활용합니다. 노드 간 tensor slicing은 커뮤니케이션 오버헤드가 크기 때문에 사용하지 않습니다. 여러 노드에서 non-expert slicing을 확장하기 위해, data parallelism을 사용하여 non-expert의 복제본을 생성하고 통신 오버헤드나 계산 세분화 감소를 유발하지 않도록 한 것입니다. 이런 방식으로 여러 parallelism 방식을 혼용해서 사용함으로써, 훨씬 큰 모델에 대해서도 scale 가능하도록 한 것이고, DeepSeek 역시 이와 유사하지만 자신들의 모델 아키텍처에 맞게 최적화된 방식을 사용합니다. 하지만 논문에서도 언급하고 있듯이 이런 방식은 통신 속도가 매우 빨라야 하는 문제가 있는 것이죠. 하드웨어 자체도 빨라야 하고, 그것들을 최적으로 사용할 수 있도록 커널도 개발이 되어야 합니다.
그래서 개인적으로 저는 PCIe를 통해 칩간 통신을 하는 가속기들이 이에 대해 어떻게 대비를 할 것인지가 궁금합니다. 점점 더 모델 파라미터는 커져감에따라, 학습 비용에 대한 압박으로 MoE와 같은 기술이 사용될 것이고, 앞으로 점점 더 "통신" 속도가 중요해 질 것 같거든요. NVIDIA는 NVLink를 사용할 수 있기 때문에 적어도 노드 내 통신에서는 큰 문제가 없는데, NVLink 보다 훨씬 느린 PCIe로 이러한 기술들을 사용할 수 있을까요? 🤔
다시 논문으로 돌아와서, expert 병렬 처리는 모든 expert 병렬 장치 간의 all-to-all 통신이 필요합니다. DeepSeek-MoE에서는 nccl을 사용하는데 있어 발생하는 오버헤드를 최적화 하기 위해 Microsoft SCCL(MCCL...) 을 사용하고, NCCL보다 더 나은 성능을 달성했습니다. 하지만 device 수의 증가에 따라 대기 시간이 선형으로 증가하는 문제가 있어, expert를 더 많은 장치로 확장하기 어렵습니다. 이 문제를 해결하기 위해, 논문에서는 P2P NCCL operation과 커스텀 CUDA 커널을 활용하여 필요한 데이터 레이아웃 변환을 수행하는 전략을 사용했습니다.

이 그림은 hierarchical all-to-all 설계를 보여주고 있습니다.
계층적 트리 기반 알고리즘은 통신 집합체인 allreduce, broadcast 등과 함께 사용되어 통신 홉 수를 줄입니다. 1부에서 잠깐 설명이 나왔었는데 먼저 local transform을 통해서, (또는 다른 최적화 아이디어를 통해 😀) 내부적으로 처리할 수 있는 데이터들을 먼저 처리하고, 또는 한 번에 통신을 몰아서 할 수 있는 방식으로 정리를 하는 것입니다. (내 노드에서 할 수 있는 청크들을 모아두고, 다른 노드로 전송할 청크를 모아두고..)
하지만 expert parallelism과 tensor parallelism, data parallelism 을 결합해서 통신 최적화 하면서 운용하는 것은 쉽지 않은 일입니다. 각 parallelism 방식 별로 (당연하게도) 동작 방식이 상이하기 때문입니다. tensor parallelism의 경우에는 각 operator들은 여러 GPU에 걸쳐 분산하고, all-reduce를 통해 연산 결과를 취합하게 되는데, expert parallelism의 경우에는 각 operator들을 분산하지 않고 각각의 GPU에 배치한 다음, expert간 all-to-all 통신을 하는 식으로, 각각의 방식의 동작이 너무 다릅니다. 그래서 눈문에서도 언급하고 있지만, 각각의 병렬처리 방식을 블랙박스로 두고, 필요한 통신만을 각각 하게 되면 개별 동작을 하는 것 대비 성능이 오히려 떨어져 버리는 문제가 생기는 것이죠.
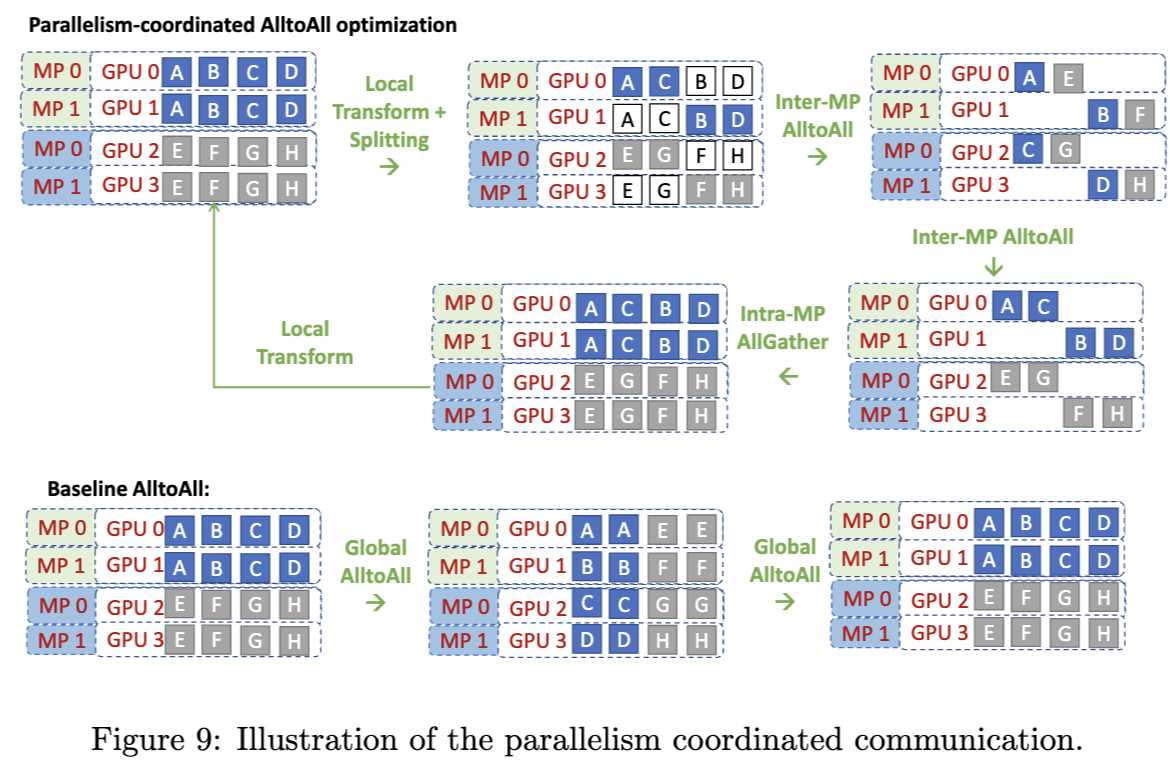
이 그림이 기본 all-to-all 연산 대비 최적화를 했을 때 어떻게 통신 오버헤드를 줄이는지를 나타내는 것입니다. 먼저 그림의 아래 쪽 basline AlltoAll을 보면, 모든 GPU에서 필요한 데이터들을 주고/받기 위해서 각각 모든 GPU와 통신을 하는 것을 알 수 있습니다. MP0의 GPU 0에 있는 A/B/C/D가 GPU 0, 1, 2, 3으로 전송되고, 다시 GPU 0로 돌아옵니다. 모든 GPU의 모든 청크에 대해서 이렇게 동작하는 것을 알 수 있죠. 그림의 위쪽에서 설명하는 parallelism-coordinated all-to-all optimization의 경우에는 먼저 각 노드 내에서 주고 받을 데이터가 정해지고, 각각 담당하는 부분을 주고 받습니다. 이렇게 함으로써 노드 간 all-to-all의 총량 자체가 줄어들게 되는 것입니다. 그리고 받은 데이터를 내 노드 안에 필요한 다른 GPU와 주고 받는 것이죠. 노드 내의 통신은 NVLink로 노드 간 통신 대비 빠르게 할 수 있기 때문에 이렇게 하면 성능이 향상 되겠죠. 바로 이런 부분 때문에 PCIe를 사용하여 통신하는 가속기들의 경우에 큰 모델을 돌릴 수록, 워크로드가 커질 수록, output이 커질 수록 문제가 심화 되지 않을까 생각하는 것입니다. NVLink 대비 대역폭이 상대적으로 매우 낮기 때문이죠.

자 이제 대망의 결과를 확인할 시간입니다. 😃
위 그림에서 X축은 사용한 GPU의 수이고, Y축은 레이턴시 및 throughput입니다. 초록색 파이토치의 레이턴시 결과 및 회색 파이토치의 througput의 결과를 보면 GPU를 더 많이 쓰더라도 레이턴시가 많이 줄어 들지 않고, throughput도 거의 변화가 없는 것을 알 수 있습니다. 레이턴시 자체도 DeepSpeed 보다 2배 이상이고, throughput도 훨씬 낮죠. DeepSpeed는 GPU 사용 대수가 많아 질수록 thgourput이 선형으로 증가하고, 레이턴시도 약간 줄어드는 것을 알 수 있습니다. 이것이 결국 모델만으로는 부족하고, 모델부터 인프라, 하드웨어까지 vertical optimization이 된 추론 시스템이 필요하다는 이유입니다.
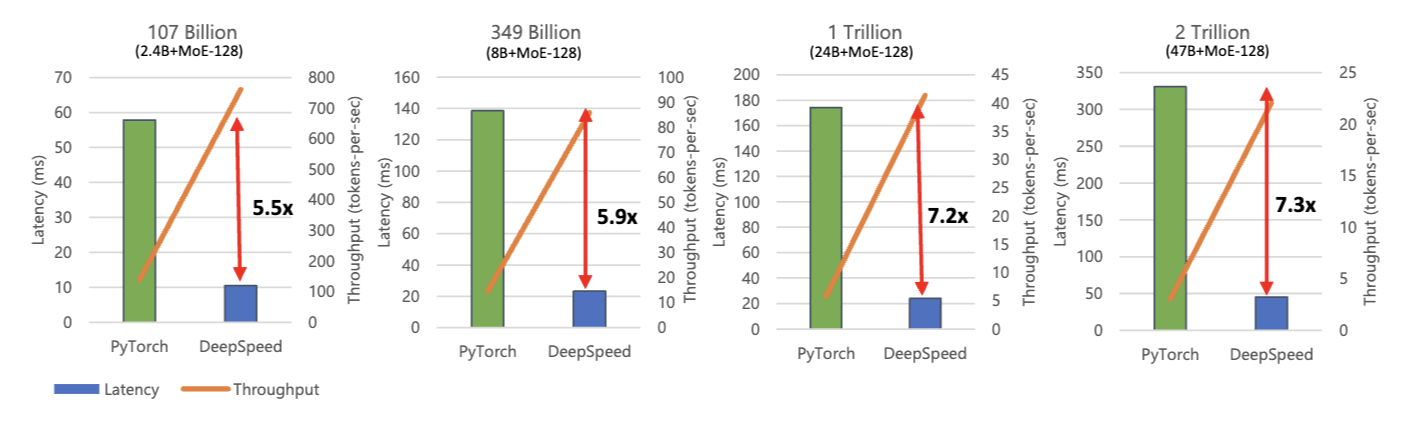
모델 크기가 커지더라도 DeepSpeed는 여전히 pytorch 대비 레이턴시, throughput 모두 뛰어나다는 것을 알 수 있죠.
논문에서는 그 외에도 여러가지 성능 개선 결과에 대한 내용을 이야기 하고 있으니 원문을 직접 확인해보셔도 좋을 것 같습니다.
끝.